
A importância da otimização na gestão de dados no desenvolvimento de jogos
Entender a relevância de armazenar dados no setor de jogos de casino é crucial para criar jogos melhores e formas de otimizar a gestão de informação. Neste artigo, conto-te tudo sobre nosso mais novo sistema de armazenamento e gestão de dados.
Qual a importância dos dados na indústria de casinos?
Na equipa de Game Development da Fabamaq, desenvolvemos jogos para casinos físicos que operam em máquinas que se podem desligar por vários motivos. Assim, os dados desempenham um papel essencial para garantir que nenhuma informação é perdida quando ocorre um problema com o jogo ou com um gabinete.
Sempre que existe uma quebra de energia, o jogo que estava em execução deveria ser capaz de restaurar o seu estado original. Por esse motivo, um modelo de persistência que possa lidar com o armazenamento e recuperação de dados nos dispositivos de persistência escolhidos (que fazem parte das máquinas do casino) é crucial.
Além disso, para fins de certificação, precisamos de ter os dados preservados em dispositivos de armazenamento específicos que fazem parte do hardware da máquina.
Vamos explorar o antigo e o novo modelo de persistência de dados utilizados nos jogos de casinos físicos que desenvolvemos.
O Atual Modelo de Persistência de Dados
O modelo atualmente adotado é baseado na construção de uma representação estática dos campos de armazenamento, com tipos e tamanhos previamente conhecidos. Isso obriga-nos, enquanto programadores, a saber exatamente quais queremos armazenar durante a compilação, o que nos faz perder tempo e flexibilidade nas nossas rotinas diárias de trabalho.

Além disso, este antigo modelo de persistência possui algumas limitações, como não ser capaz de distinguir entre ter valores nulos ou zero e não ter um valor salvo num determinado campo.
Um olhar atento sobre o Novo Modelo de Persistência de Dados
Tendo estas limitações em mente, encontramos uma solução que aborda estes problemas, oferecendo ao cliente que usa a biblioteca de armazenamento a versatilidade de guardar qualquer tipo e tamanho de dados necessários, sem comprometer os requisitos do sistema que não podem ser alterados.
Depois de testar outras soluções, percebemos que essas opções não atendiam totalmente às nossas necessidades, então implementamos o nosso próprio motor de banco de dados.
Visão geral de um novo conceito criado in-house
Ser capaz de economizar tempo e aumentar a produtividade entre as equipas de Game Dev foi o lema para a criação do nosso novo modelo de persistência, que foi levemente baseado no conceito de um version control system.
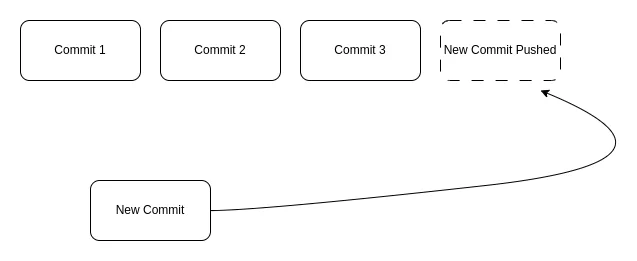
Em termos simples, cada operação de dados - seja adicionar ou remover - é organizada num bloco chamado commit. Esses commits são atómicos em relação a uma única operação de dados para um determinado bloco e são processados para serem enviados e arquivados nos dispositivos de persistência definidos.
Existem vários dispositivos de persistência, como NVRAM e arquivos de log, nos quais os dados comprometidos são armazenados. Todos os dados são compostos por pares de key-values, nos quais os valores podem ser do tipo que o cliente decidir, alcançando assim a flexibilidade em tempo de execução que desejávamos desde o início.
Sempre que queremos aceder a um bloco de informação de um dispositivo de persistência, contamos que esse bloco tenha sido guardado seguindo a estrutura seguinte, o que nos ajuda a interpretá-lo de forma padronizada.
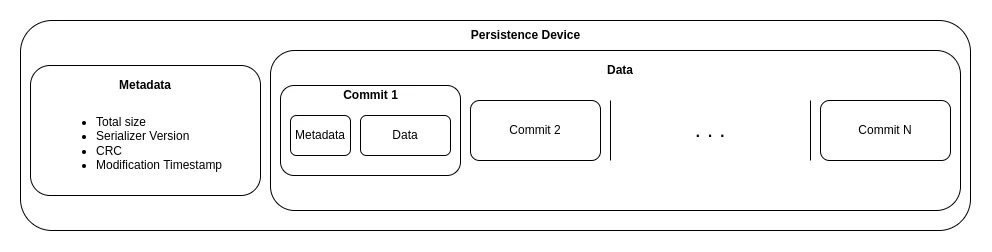
Quando é solicitada uma atualização de valor de um determinado campo de dados, um novo commit é enviado e, devido à natureza do modelo, o último commit enviado é aquele que contém o estado atual desse campo de dados. Se for solicitada a exclusão de um campo de dados, o mesmo processo ocorre.
Visão geral da Arquitetura
Talvez te estejas a perguntar... este novo conceito parece excelente, mas como podemos implementar um sistema destes de forma prática? O sistema de persistência é organizado nos seguintes componentes:
Data Store
A sua responsabilidade é manter uma representação dos dados armazenados num objeto JSON localmente acessível.
Também serve como um proxy que encaminha as chamadas para operações de dados (salvar, obter, excluir), que são implementadas no respetivo objecto CommitEngine.
Persistence Controller
Este controller lida e gere os objetos DataStore, a sua criação, exclusão e acesso.
Commit Engine
Este é o coração de todo o modelo, pois aqui está a lógica para processar todas as operações de dados.
O objeto CommitEngine possui uma instância de um CommitsSerializer específico e o solicita-o para (des)serializar e obter/salvar os dados solicitados pelo cliente.
Context Manager
Lembras-te dos dispositivos de persistência e da estrutura de commits mencionada no diagrama acima? O Context Manager gere esses layouts de dados e valida a sua integridade para evitar o acesso a dados corrompidos.
Commits Serializer
É importante observar que os dados não são preservados nos dispositivos de persistência na sua forma legível, pois isso representaria uma pegada de memória maior nesses dispositivos. Portanto, os dados são serializados com MessagePack, que oferece alguma compressão de dados.
O Serializer é, também, responsável por deserializar os dados num commit quando uma operação de obtenção de dados é solicitada. A forma como o sistema mantém uma referência local dos dados armazenados também depende da versão do Serializer.
Considera este exemplo: uma versão instrui o objeto DataStore a manter uma representação direta do banco de dados completo no seu objeto JSON, enquanto há outra versão que instrui a manter apenas um mapa de memória para cada key-value, que consiste no endereço do valor para aquela key e no tamanho dos dados salvos com aquela key. Este último ajuda na otimização de memória.
Persistence Devices
Finalmente, cada tipo de dispositivo de persistência possui um objeto respetivo, responsável por operações relacionadas ao dispositivo, como a lógica específica de leitura e gravação.
No próximo capítulo...
Neste artigo, exploramos o mundo dos dados no setor de jogos, bem como os modelos de persistência antigos e novos adotados para melhorar a otimização de memória. Fiquem atentos ao próximo conteúdo, onde vamos desvendar o processo de implementação das operações de dados utilizando a nova ferramenta desenvolvida pela Fabamaq.
Artigo escrito por Diogo Pereira, Game Developer na Fabamaq.


