
The importance of Data management optimization in Game Development
Understanding the relevance of storing data in the casino gaming sector is crucial to create better games and ways to optimize information handling. In this article, I tell you all about Fabamaq's newest data storage and management system.
Why is data so important in the casino industry?
In the Game Developmentteam at Fabamaq, we develop games for land-based casinos which run in machines that can go off power for several reasons. As such, data plays a big role in guaranteeing no information is lost whenever a problem occurs with the game or casino cabinet.
Every time a power outage occurs, the game that was running should be able to restore to its original state. For that reason, a persistence model that can handle the data storing and retrieving from the chosen persistence devices (which are part of the casino machines) is crucial.
Additionally, for certification purposes, we need to have data stored in specific storage devices that are part of the machine’s hardware.
Let’s dive into old and new persistence model approaches in the land-based casino games we develop.
Inside the Current Data Persistence Model
The currently adopted model is based on building a static representation of storage fields, with previously known types and sizes. This forces us as developers to know exactly which ones we want to store in compile time, which makes us lose time and flexibility in our daily work routines

Furthermore, this old persistence model has some limitations, such as not being able to distinguish between having null or zero values and not having a value saved in a certain field.
A closer look into the New Data Persistence Model approach
Having those setbacks in mind, we found a solution that tackles these problems, offering the client who is using the storage lib the versatility to store whatever data type and size needed, without compromising the non-negotiable system requirements.
After testing other out-of-the-box solutions, we realized that those options were not a tight match to our needs, so we kind of implemented our own database engine.
Overview of a new concept created in-house
Being able to save time and increase productivity among our Game Development teams was the motto for the creation of our new persistence model, which was loosely based on the concept of a basic version control system.
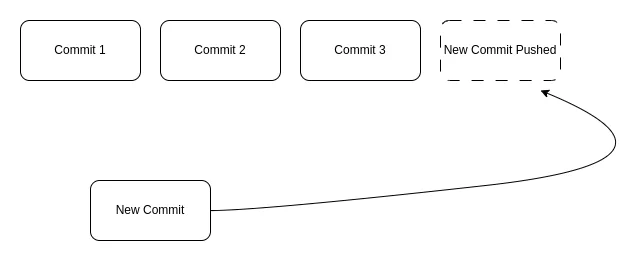
In simple terms, each data operation, regardless it is an addition or a removal, is organized in a block called commit. These commits are atomic, regarding a single data operation for a given data block, and are processed to be pushed and archived in the defined persistence devices.
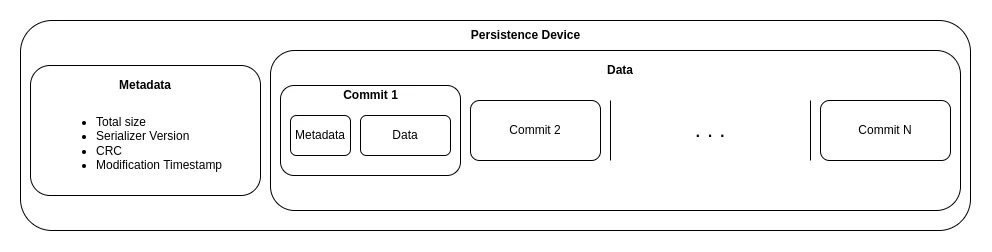
There are several persistence devices, such as NVRAM, and log files, in which the committed data is stored. All data is composed of key-value pairs, in which the values can be of whatever type the client decides, hence achieving the runtime flexibility we wanted in the first place.
Whenever we wish to access a piece of information from a persistence device, we rely on it to have been stored by obeying the following structure, which helps us parse it in a standard way.
When a value update of a given data field is requested, a new commit is pushed, and given the nature of the model, the last commit pushed is the one that holds the current state of that data field. If a data field deletion is requested, the same process occurs.
Architectural Overview
You might be wondering… the new concept sounds great, but how can we implement a system like this in a practical way? Well, the persistence system is organized into the following components:
Data Store
Its responsibility is to hold a representation of stored data locally in an accessible JSON object.
It also serves as a proxy that forwards the calls for data operations (save, get, delete), which are implemented in the respective CommitEngine object.
Persistence Controller
This controller handles and manages the DataStore objects, their creation, deletion, and access.
Commit Engine
This is the heart of the whole model, as here lies the logic to process all data operations.
The CommitEngine object holds an instance of a specific CommitsSerializer and asks it to (de)serialize and get/save the requested data by the client.
Context Manager
Remember the persistence devices and commits structure mentioned in the diagram above? The Context Manager manages those data layouts and validates their integrity to avoid accessing corrupted data.
Commits Serializer
It is important to note that data is not preserved in persistence devices as is, because it would represent a bigger memory footprint in those devices. So, the data is serialized with MessagePack, which offers some data compression.
The serializer is also responsible for deserializing the data in a commit when a get data operation is requested. The way the system holds a local reference of the stored data is also dependent on the serializer version.
Take this example: one version tells the data store object to hold a direct representation of the whole database in its JSON object, while there’s another version that tells to only hold a memory map for each data key, that consists of the address of the value for that key and the size of the data saved with that key. The latter helps with memory optimization.
Persistence Devices
Finally, each persistence device type has a respective object, responsible for device-related operations, such as read and write specifics.
In the next chapter…
In this article, we've explored the world of data in the Gaming sector, as well as the old and new persistence models adopted to improve memory optimization. Stay tuned for the next content where we will be unravelling the process of implementing data operations under the new tool developed by Fabamaq.
Article written by Diogo Pereira, Game Developer at Fabamaq


